Linguagem R

21/09/2023
Linguagem R
Testes de hipóteses estão, sem dúvida alguma, entre os métodos estatísticos mais proeminentes dentro da pesquisa científica. A possibilidade de se testar uma suposição a respeito do comportamento de uma ou mais variáveis aleatórias a partir de uma amostra de observações dessas variáveis abriu portas para a utilização da Estatística nos mais diversos campos da ciência, desde as áreas sociais, comportamentais e médicas, à área física, química e muitas outras. Ao longo deste post, entretanto, não trataremos especificamente de testes de hipóteses – assunto que já foi explorado pelo OOBr -, mas sim de um elemento intrínseco a essas ferramentas: o valor-p. O valor-p (também chamado de p-valor ou valor de p) é uma probabilidade relacionada à amostra observada que fornece uma dimensão da “compatibilidade” dessa amostra com a hipótese nula que está sendo testada, nos dando, assim, uma base para a tomada de decisões. Ao longo desta publicação, trataremos da origem dessa ferramenta, de sua definição formal, dos aparentes benefícios de sua utilização – e dos malefícios de sua má-utilização – e discutiremos maneiras de se contornar suas limitações, que estão sendo cada vez mais evidenciadas dentro do meio científico. É importante dizer que este texto irá assumir que o leitor já possui conhecimentos prévios dos conceitos básicos relacionados à teoria dos testes de hipóteses. Assim, caso esse não seja o seu caso, ou caso deseje relembrar alguns desses conceitos, sugerimos a leitura do post a respeito de testes de hipóteses produzido pelo OOBr, disponível neste link.
A origem do valor-p pode ser atribuída a Ronald Fisher, o famoso estatístico inglês considerado um dos pais da Estatística moderna. Em seu livro “Statistical Methods for Research Workers”, publicado em 1925, Fisher apresenta uma série de exemplos de experimentos em que calcula valores-p para o que chamava de testes de significância, um método de testagem de hipóteses desenvolvido por este autor que precede a teoria de testes de hipóteses desenvolvida por Jerzy Neyman e Egon Pearson publicada em 1928 e difundida na grande maioria dos livros didáticos atuais. A ideia era utilizar a probabilidade fornecida pelo valor-p para se decidir sobre a significância dos resultados obtidos, ou seja, decidir se os dados poderiam ser utilizados, ou não, para se rejeitar a hipótese nula proposta, seja ela referente à igualdade entre os efeitos de tratamentos, à adequação de um conjunto de dados a uma certa distribuição de probabilidades ou à independência entre duas variáveis categóricas.
A ideia por trás do valor-p é, de certa forma, simples (mas frequentemente mal entendida): ele representa a probabilidade de observarmos valores da estatística de teste tão extremos quanto o observado, sob a suposição de a hipótese nula ser verdadeira. Dessa forma, quanto menor o valor-p, mais incompatíveis são os dados observados com a hipótese nula formulada; assim, quando o valor-p é suficientemente pequeno, encaramos essa incompatibilidade como sendo uma evidência de que a hipótese nula não é aceitável e, portanto, deve ser rejeitada. É comum lermos e dizermos que um valor-p é significativo quando ele é baixo o suficiente para se rejeitar uma hipótese nula. O sentido original da palavra “significativo”, entretanto, foi se modificando com o passar do tempo, como explica David Salsburg em seu livro “Uma senhora toma chá”, publicado em 2002: quando a teoria por trás do valor-p estava sendo desenvolvida, ser “significativo” representava apenas que o cálculo significou ou mostrou alguma coisa. O sentido atual da palavra, por outro lado, remete a algo ser muito importante, e é nesse sentido que muito se fala, erroneamente, que um certo resultado foi significativo. Como veremos posteriormente, a utilização dos termos “significativo” e “não significativo” está sendo, nos anos recentes, um dos vários pontos de debate dentro da comunidade estatística, com muitos defendendo abandonar a utilização dessas expressões, por conta da conotação potencialmente enganosa e perigosa que elas podem carregar.
Até este ponto, nos limitamos a dizer que decidimos rejeitar uma hipótese nula caso o valor-p obtido seja suficientemente pequeno. Ser “suficientemente pequeno” é, entretanto, outra definição problemática dentro da Estatística. É discutível se Fisher definiu que valores-p menores que 0,05 são “significativos” e devem levar à rejeição da hipótese nula, mas é fato que esse número passou a ser visto como um grande critério universal para a tomada de decisões estatísticas. Experimentos que falham em atingir esse valor são frequentemente descartados, enquanto aqueles que o atingem são tratados como os que realmente importam. A atribuição da definição desse critério padrão do valor-p a Fisher se deve, possivelmente, a uma afirmação feita por este autor em seu artigo “The Statistical Method in Psychical Research”, publicado em 1929, no qual Fisher diz que “é prática comum julgar um resultado significativo se ele é de tal magnitude que possa ser reproduzido por acaso não mais frequentemente que uma vez em 20 tentativas” e que “esse é um nível arbitrário, mas conveniente, de significância para o investigador prático”. Nesse mesmo artigo, Fisher diz, ainda, que “o teste de significância só informa o que ignorar, a saber, todos os experimentos nos quais resultados significativos não são obtidos” e que “o investigador deveria apenas afirmar que um fenômeno é experimentalmente demonstrável quando sabe como planejar um experimento de forma que raramente falhe em dar um resultado significativo”. Dessa forma, de acordo com o autor, “resultados significativos isolados, que ele não sabe como reproduzir, são deixados em suspenso para futura investigação”.
Como podemos notar, Fisher considera que a significância de um resultado só está realmente demonstrada se a grande maioria de um conjunto de experimentos idênticos se mostra individualmente significante. Essa definição, entretanto, se perdeu ao longo do tempo, e definitivamente não é considerada na maior parte dos estudos e pesquisas científicas. Por outro lado, existe uma grande problemática na fala de que “o teste de significância só informa o que ignorar, a saber, todos os experimentos nos quais resultados significativos não são obtidos”, uma vez que falhar em obter a significância não é prova de que o efeito que se deseja mostrar não existe. Mas, ponhamos em pausa essa discussão para o presente momento – voltaremos a ela numa seção específica – e partamos para a apresentação de como incorporamos o valor-p à teoria de testes de hipóteses que estamos acostumados a conhecer.
Quando temos o primeiro contato com a teoria relacionada a testes de hipóteses, é comum que, para decidirmos quanto à rejeição ou não de uma hipótese nula, sigamos o seguinte processo:
1. definimos a hipótese nula a ser testada, H0, bem como a hipótese alternativa, H1;
2. definimos a estatística que será utilizada para se testar a hipótese nula, cuja distribuição de probabilidades assumindo H0 como verdadeira deve ser conhecida;
3. fixamos o nível de significância α do teste, ou seja, a probabilidade de rejeitarmos a hipótese nula quando ela é verdadeira;
4. construímos, com base no nível de significância adotado e assumindo H0 como verdadeira, a região crítica, que representa o conjunto de valores da estatística de teste que levariam à rejeição da hipótese nula caso fossem observados;
5. calculamos, utilizando as observações obtidas em uma amostra, o valor da estatística de teste;
6. caso o valor observado da estatística de teste não pertença à região crítica, não rejeitamos H0; caso contrário, a hipótese nula é rejeitada.
Como podemos perceber, o procedimento padrão de um teste de hipóteses parte da fixação de um nível de significância α, sendo a construção da região crítica dependente desse valor. Assim, caso fosse de nosso interesse verificar se a hipótese nula seria rejeitada sob um valor diferente de α, teríamos de reconstruir a região de rejeição. Fazendo uso do valor-p para a tomada de decisões, por outro lado, a fixação do nível de significância de antemão e a construção da região crítica já não são mais necessárias: depois de calculado o valor da estatística de teste, podemos encontrar a probabilidade de observarmos valores dessa estatística tão extremos quanto o observado sob a suposição de H0 ser verdadeira – ou seja, o valor-p -, rejeitando a hipótese nula caso essa probabilidade seja menor que um certo valor de α. É importante notar que, por mais que a fixação do nível de significância de antemão não seja estritamente necessária para a realização de um teste de hipóteses que utiliza o valor-p, é recomendado que o valor de α seja, sim, definido de forma prévia à realização do teste, para que o pesquisador não seja induzido a mudar seu critério de rejeição de acordo com os resultados obtidos.
Para fixarmos os conceitos aqui discutidos, vejamos um exemplo simples. Suponha que, após 100 lançamentos de uma moeda, 37 caras tenham sido observadas, e que seja de nosso interesse verificar se essa moeda é honesta utilizando um nível de significância de 1%. Reescrevendo esse problema de maneira formal, seja X a variável aleatória que conta o número de caras que ocorreram ao longo dos 100 lançamentos da moeda. Sabemos, então, que X segue distribuição binomial com parâmetros n = 100 e p, sendo p – a probabilidade de se observar uma cara – um valor desconhecido. Como é de nosso desejo verificar se a moeda é honesta, e como sabemos que uma moeda honesta tem probabilidade 0,5 de resultar em cara ou coroa, queremos testar as seguintes hipóteses:
![]()
Note que, como observamos poucas caras na amostra, podemos suspeitar de que a probabilidade de se obter uma cara por meio dessa moeda seja menor que a probabilidade de 0,5 que esse evento teria caso a moeda fosse honesta e, por isso, definimos a hipótese alternativa de forma a obtermos um teste unilateral à esquerda. Dessa forma, caso rejeitássemos a hipótese nula, poderíamos dizer que teríamos evidências para acreditar que a probabilidade de se obter uma cara a partir da moeda em questão é menor que 0,5. Para a resolução deste problema, precisamos, primeiramente, definir a estatística de teste a ser utilizada. Como estamos tratando de uma proporção, utilizar o estimador da proporção amostral, dado por
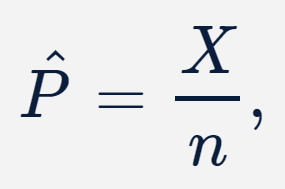
parece ser uma boa pedida, em especial porque conhecemos sua distribuição aproximada sob H0. Calculando, assim, o valor dessa estatística, sabendo que n = 100 e que o número observado de caras foi de x = 37, obtemos
![]()
Determinado o valor observado da estatística de teste, precisamos, então, calcular o valor-p. Como o tamanho da amostra é suficientemente grande, sabemos, como consequência do Teorema do Limite Central e de forma aproximada, que
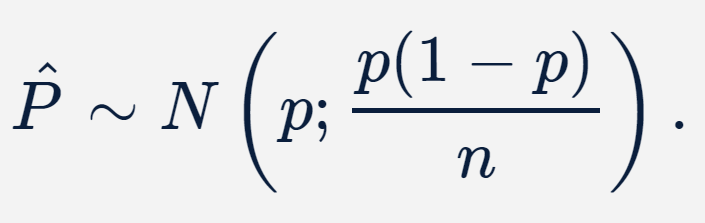
Supondo H0 verdadeira, ou seja, que p = 0,5, a distribuição do estimador da proporção amostral fica completamente especificada, a saber,
![]()
Dessa forma, como encontramos que
![]()
podemos calcular, padronizando a variável aleatória
![]()
a probabilidade de observarmos valores tão extremos quanto esse supondo que a moeda seja honesta, ou seja,
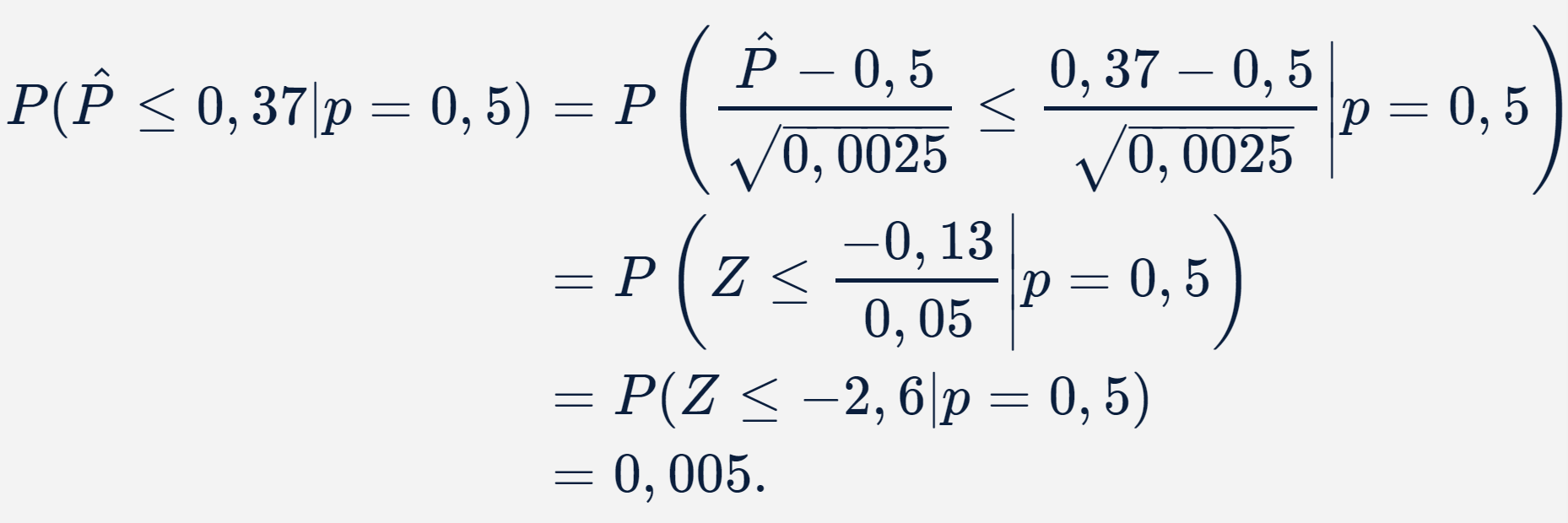
Como o valor-p obtido foi de 0,005, podemos dizer que, se a moeda fosse realmente honesta, a probabilidade de encontrarmos uma amostra de 100 lançamentos com 37% ou menos ocorrências de caras seria de 0,5%. Isso sugere que, ou estamos diante de uma amostra muito rara, que deve ocorrer 1 vez a cada 200 realizações do experimento, ou que a hipótese nula formulada não é aceitável. Como adotamos um nível de significância de 1%, e como o valor-p obtido foi menor que esse nível de significância, somos levados a decidir pela rejeição da hipótese nula. Dessa forma, temos evidências para acreditar que a moeda em questão não é honesta (ela, de fato, não era; o valor 37 foi gerado aleatoriamente a partir da distribuição binomial com p = 0,3, utilizando a semente 42 e a função rbinom(), disponível no pacote stats{}, do R).
Para finalizar esta seção, uma observação importante a se fazer é a respeito do cálculo do valor-p para testes de hipóteses bilaterais, ou seja, aqueles cuja hipótese alternativa é do tipo θ ≠ θ0, sendo θ um parâmetro qualquer. Nesses casos, um possível procedimento é tomar o valor-p bilateral como sendo o dobro do valor-p unilateral. Quando a distribuição da estatística de teste sob H0 é simétrica, como no caso da distribuição normal e da distribuição t de Student, esse procedimento é razoável. Em outras situações, pode ser preferível relatar o valor do valor-p unilateral e a direção segundo a qual a observação se afasta de H0. Para mais detalhes, sugerimos a leitura da seção referente ao valor-p dentro do livro “Estatística básica”, escrito por Bussab e Morettin e publicado em 2010.
Em sua superfície, a utilização do valor-p fornece uma maneira padronizada e objetiva de se quantificar a evidência estatística, aparentando impedir que julgamentos subjetivos e outros tipos de vieses influenciem as conclusões do pesquisador (apesar de a própria escolha de um certo nível de significância, por exemplo, ser uma decisão subjetiva). Além disso, a praticidade oferecida pelo valor-p pesa positivamente para a continuidade de sua utilização, uma vez que, por se tratar aparentemente de um único número que resume toda uma análise, ele é de fácil comunicação e reporte. Por essas e outras razões, a utilização do valor-p se espalhou fortemente dentro do meio científico, tornando cada vez maior a quantidade de publicações que fazem mal uso dessa medida. Um dos erros mais comumente cometidos é referente à interpretação do significado do valor-p: diferente do que pesquisadores desavisados possam acreditar, o valor-p não fornece a probabilidade de a hipótese nula ser falsa – até porque, dentro da Inferência Clássica, calcular a probabilidade de um parâmetro estar dentro de um intervalo de valores não faz sentido, uma vez que, aqui, parâmetros são tratados como constantes.
Além disso, como nota o próprio Fisher ao comentar sobre o cálculos de valores-p para testes qui-quadrado em seu livro “Statistical Methods for Research Workers”, essa medida não representa o grau da associação entre duas variáveis ou o grau da diferença entre dois efeitos; ela fornece apenas uma ideia de se essas associações ou diferenças são ou não de uma magnitude que pode ser atribuída ao acaso. Dessa forma, valores-p pequenos não definem, necessariamente, que um resultado encontrado tem grande relevância prática. Tomando como exemplo um estudo que busque encontrar diferenças entre tratamentos, por mais que o valor-p possa revelar a existência de evidências para se acreditar que dois efeitos são estatisticamente diferentes, essa diferença pode ser tão pequena a ponto de, na prática, ela não ser realmente significativa. Qualquer efeito, não importa quão mínimo, pode produzir um valor-p pequeno se o tamanho da amostra e a precisão das medições forem grandes o suficiente, e efeitos grandes podem produzir valores-p pouco impressionantes caso a amostra seja pequena e as medições forem imprecisas. Dessa forma, a utilização única e exclusivamente do valor-p para se decidir sobre a “significância” de um experimento vem sendo cada vez mais criticada, em especial porque, como já citado ao longo do texto, o termo “significante” deixou de denotar que um resultado merece uma investigação mais aprofundada e passou a ser sinônimo de importância científica.
A discussão a respeito da má utilização do valor-p chegou, possivelmente, ao seu ápice em 2016, quando a American Statistical Association (ASA) publicou o artigo “The ASA Statement on p-Values: Context, Process, and Purpose”, que contém uma discussão a respeito do verdadeiro significado do valor-p e dos princípios relacionados a sua utilização. Desde então, a comunidade estatística passou a enfatizar cada vez mais a importância de se complementar – ou mesmo de se substituir – a utilização do valor-p, sendo muito recomendada a utilização de métodos que focalizem o processo de estimação, tais como intervalos de confiança e de predição, razões de verossimilhança e métodos Bayesianos, como intervalos de credibilidade e fatores de Bayes. Mesmo que todas essas práticas sejam dependentes de outras suposições, elas podem fornecer mais diretamente a dimensão do tamanho de um efeito – e de sua incerteza associada – ao invés de focar apenas na questão de uma hipótese ser “correta” ou não.
Em suma, é no mínimo discutível que um único número substitua todo o processo científico que está por trás de uma análise estatística, e a insistência nesse erro é um grande empecilho para uma boa prática científica, para a qual boas práticas estatísticas são um componente essencial. Dessa forma, em vez de se confiar unicamente no valor-p – que tem, é claro, a sua utilidade – para se decidir sobre a relevância de um estudo, um bom pesquisador deve focar em entender os princípios de um bom planejamento experimental, do valor que análises descritivas têm dentro de um estudo estatístico, da importância de se entender o fenômeno em estudo e da necessidade de se interpretar os resultados de uma análise dentro do contexto correto, de forma a se alcançar o verdadeiro entendimento a respeito das medidas encontradas ao longo de todo o processo realizado.
Fisher, Ronald A. “Statistical methods for research workers”. Breakthroughs in statistics: Methodology and distribution. New York, NY: Springer New York, 1970. 66-70.
Fisher, Ronald A. “The Statistical Method in Psychical Research”. Proceedings of the Society for Psychical Research, 38, 189-192.
Neyman, J. e Pearson, E. S. (1928). “On the use and interpretation of certain test criteria for purposes of statistical inference”. Biometrika, 20A, 175–240.
Morettin, P. A. e Bussab, W. de O. Estatística Básica. 10. ed. São Paulo: Saraiva, 2010.
Salsburg, David S. Uma senhora toma chá… como a estatística revolucionou a ciência no século XX. Rio de Janeiro: Zahar, 2009.
Wasserstein, Ronald L., and Nicole A. Lazar. “The ASA statement on p-values: context, process, and purpose.” The American Statistician, 70.2 (2016): 129-133.