Linguagem R

15/03/2022
Linguagem R
Nesse post, iremos conhecer sobre o conceito de função de verossimilhança, um tema de extrema importância na inferência estatística. Discutiremos sobre algumas de suas utilizações e realizaremos exemplos práticos e computacionais que nos permitam absorver melhor as ideias que aqui forem abordadas. Para começo de conversa, quando estudamos a Teoria das Probabilidades, nos habituamos a ter um conhecimento prévio sobre a distribuição de probabilidade que uma determinada variável aleatória segue, podendo, assim, obter respostas para os possíveis eventos que podem vir a acontecer em relação a essa variável. Em situações cotidianas, entretanto, pode ser extremamente difícil de se obter precisamente as distribuições de probabilidade de certas variáveis aleatórias. Na maior parte dos casos, o melhor que podemos fazer é obter uma amostra da população que queremos estudar, e, a partir dessa amostra, inferenciar sobre a população em questão. Temos aqui uma mudança de perspectiva: se antes estávamos interessados em calcular a probabilidade de uma variável aleatória assumir um certo valor, dado que ela segue uma certa distribuição de probabilidade, agora queremos estudar sobre como deve ser essa distribuição de probabilidade, dado que observamos certos valores dessa variável aleatória na amostra.
Considere f_X(x|θ) como sendo a função densidade conjunta (no caso contínuo) ou a função de probabilidade conjunta (no caso discreto) de n variáveis aleatórias. Definimos a função de verossimilhança L(θ|x) como sendo a função densidade (ou de probabilidade) conjunta dessas n variáveis aleatórias vista como função de θ, ou seja, considerando como fixos os valores de X1,X2,…,Xn e variando o valor do parâmetro θ (ou valores, caso θ seja um vetor de parâmetros). Em outras palavras, temos que L(θ|x)=f_X(x|θ)
Apesar de, à primeira vista, a definição acima parecer ser simplesmente uma diferença de notação, a função de verossimilhança e a função densidade (ou de probabilidade) conjunta apresentam distinções importantíssimas. Em primeiro lugar, algo a se notar é que a função de verossimilhança, por ser uma função de θ, pode ser contínua em um certo intervalo mesmo que f_X(x|θ) seja uma função de probabilidade conjunta (ou seja, mesmo que as variáveis aleatórias que fazem parte da amostra sejam discretas). Basta que θ assuma valores de forma contínua em um dado intervalo. Além disso, é preciso deixar claro que a função de verossimilhança não é uma função densidade (ou de probabilidade) em relação a θ, pois sua integral (ou soma) em todo o espaço paramétrico (conjunto de todos os possíveis valores que o parâmetro pode assumir) não necessariamente é igual a 1, propriedade que deve ser cumprida para que uma função seja considerada uma função densidade de probabilidade ou uma função de probabilidade. Dessa forma, o valor obtido através da função de verossimilhança não pode ser considerado como uma densidade de probabilidade ou uma probabilidade em relação a θ. De fato, chamamos, pásmem, de verossimilhança o valor obtido por meio dessa função. Mas, afinal… o que seria, então, essa verossimilhança?
Para explicar o que é, de fato, a verossimilhança, precisamos definir dois cenários diferentes. Para o primeiro caso, o caso discreto, considere uma amostra aleatória (X1, X2, X3, X4) na qual todas as variáveis seguem uma distribuição Bernoulli(θ), onde θ é a probabilidade de sucesso, variando no intervalo [0,1]. Suponha que os valores observados de (X1, X2, X3, X4) tenham sido x1=0, x2=1 ,x3=1 e x4=1, e que queremos decidir entre duas hipóteses: a hipótese A, na qual o verdadeiro valor do parâmetro seria θ=0,5, e a hipótese B, na qual o valor de θ seria 0,8. Por se tratar de uma amostra aleatória, consideramos que todas as variáveis são independentes e identicamente distribuídas (i.i.d.). Dessa forma, a função de probabilidade conjunta pode ser escrita como sendo o produtório das funções de probabilidade marginais (é de extrema importância lembrar que essa afirmação é válida se, e somente se, as variáveis aleatórias em questão são independentes). Assim, para x∈{0,1}, temos:

Sendo ∑xi=0+1+1+1=3,
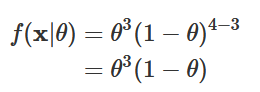
Assim, L(θ|x)=θ^{3}(1−θ), para 0⩽θ⩽1. Note que, como f_X(x|θ) é uma função de probabilidade conjunta e, portanto, está limitada ao intervalo [0,1], a função de verossimilhança também estará limitada a esse intervalo. Antes de continuarmos a resolução do exemplo, podemos ilustrar que, como dito na seção anterior, a integral da função de verossimilhança em todo o seu domínio não necessariamente deve ser igual a 1. Observe os cálculos abaixo.
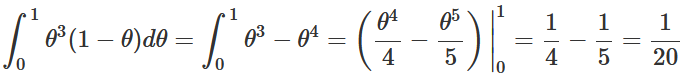
Dessa forma, reforçando, L(θ|x) não pode ser considerada uma função densidade de probabilidade em relação a θ. Voltando ao exemplo, queríamos decidir entre as hipóteses A, na qual θ=0,5, e B, na qual θ=0,8. No primeiro caso, o valor da verossimilhança seria dado por:

Já no segundo caso,

Quanto à interpretação dos resultados, não podemos dizer, de forma alguma, que a verossimilhança indica que a probabilidade do verdadeiro valor de θ ser 0,5 é de 0,0625, ou que a probabilidade de θ ser 0,8 é de 0,1024. O valor da verossimilhança, quando X é discreto, deve ser interpretado como sendo a probabilidade de observarmos os valores da amostra caso o verdadeiro valor do parâmetro seja o valor testado. Assim, a verossimilhança seria uma probabilidade em relação a X, e não em relação a θ. Com isso, como 0,1024 > 0,0625, concluímos que a amostra em questão tem uma maior chance de ser observada quando θ=0,8, e, portanto, a hipótese B é mais verossímil do que a hipótese A. Podemos ainda definir a razão de verossimilhança, dada por

como sendo uma forma de medir a força de evidência em favor da hipótese B sobre a hipótese A. Nesse exemplo, temos que

Assim, podemos dizer que a observação da amostra obtida é evidência de que a hipótese B é aproximadamente 1,64 vezes mais verossímil do que a hipótese A.
Analogamente, caso (X1, X2, …, Xn) fosse uma amostra de variáveis aleatórias que seguem uma distribuição contínua, teríamos que f_X(x|θ) seria uma função densidade conjunta, e que, por estar definida em [0,∞), assim o estaria a função de verossimilhança. O valor da verossimilhança, nesse cenário, indicaria a densidade de probabilidade da amostra observada caso o verdadeiro valor de θ fosse o valor testado. Novamente, a densidade de probabilidade é em relação a X, e não em relação a θ. De qualquer forma, encontrar o valor de θ que maximiza uma função de verossimilhança aparenta ser um bom caminho para estimar o verdadeiro valor do parâmetro de uma distribuição de probabilidade. E é exatamente sobre isso que discutiremos na próxima seção.
No ramo da inferência estatística, um dos métodos mais conhecidos e dominantes de se estimar um parâmetro de uma certa distribuição de probabilidade, dado os valores observados em uma amostra, é o chamado método da máxima verossimilhança. A ideia principal desse método consiste em maximizar o valor da função de verossimilhança, para que assim a probabilidade de a amostra observada ocorrer seja a maior possível. Dessa forma, sendo L(θ|x) a função de verossimilhança das variáveis aleatórias X1, X2, …, Xn, chamamos de estimador de máxima verossimilhança e denotamos por θ^, sendo θ^(X1, X2 ,…, Xn) (ou seja, uma função das variáveis aleatórias), o valor de θ que, entre todo o espaço paramétrico, maximiza L(θ|x). Quando substituídos os valores observados de X1, X2, …, Xn, obtemos a chamada estimativa de máxima verossimilhança para θ.
Para maximizar a função de verossimilhança, buscaremos auxílio no Cálculo. Respeitadas algumas condições, temos que o estimador de máxima verossimilhança é a solução da equação
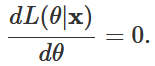
Para que as explicações acima fiquem mais claras, passemos para um exemplo. Considere que (X1, X2, …, Xn) é uma amostra aleatória de uma distribuição Bernoulli(θ). De forma semelhante ao que vimos na seção anterior, podemos escrever a função de probabilidade conjunta dessas variáveis, para x∈{0,1} como sendo
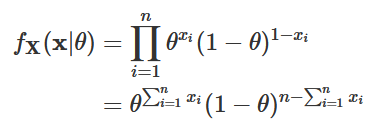
Logo, L(θ|x)=θ∑xi(1−θ)^{n−∑xi} para 0⩽θ⩽1. Para encontrarmos o estimador de máxima verossimilhança de θ, precisamos derivar a função L(θ|x) em relação a θ e igualar o resultado a zero. Note, entretanto, que na maioria dos casos é consideravelmente mais fácil encontrar a derivada do logaritmo da função de verossimilhança do que a derivada da função de verossimilhança propriamente dita. E como a função logarítmica é estritamente crescente, maximizar a função de verossimilhança é o equivalente a maximizar a função de log-verossimilhança. Para não causar maiores confusões, denotaremos essa última por l(θ|x), sendo l(θ|x)=log[L(θ|x)]. Assim, temos:
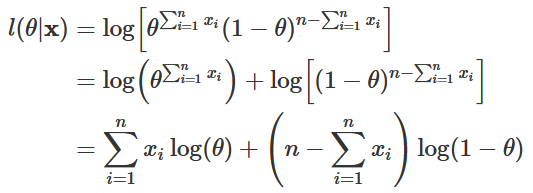
Calculando a derivada em relação a θ,
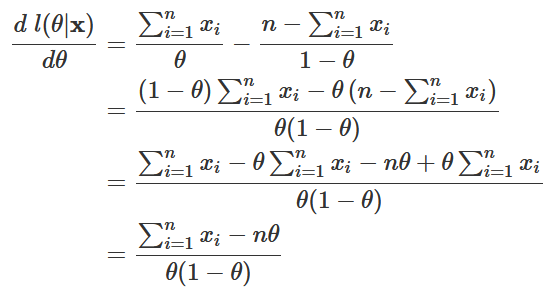
O resultado acima – a derivada da função de log-verossimilhança – recebe um nome especial: a chamamos de função escore, denotada por s(θ). Igualando-a a zero, temos:
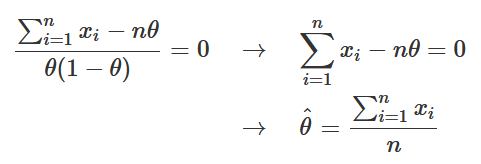
Logo, o estimador de máxima verossimilhança para θ de uma amostra aleatória com distribuição Bernoulli(θ) é θ^=X¯, ou seja, a média amostral. Aplicando esse resultado no exemplo discutido na seção anterior, no qual n=4 e x1=0, x2=1, x3=1 e x4=1, temos:
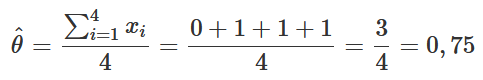
Assim, a estimativa de máxima verossimilhança para θ é de 0,75. Ou seja, a maior probabilidade de observarmos a amostra em questão ocorre quando o valor do parâmetro populacional é 0,75. Nesse ponto, a verossimilhança é dada por

Note que, como esperado, o valor acima é maior que o valor encontrado para a verossimilhança quando θ=0,8, calculado anteriormente. Assim, podemos considerar que uma hipótese C, que diz que o verdadeiro valor do parâmetro é 0,75, é a hipótese mais verossímil para explicar o comportamento de θ. Muito importante: isso não significa que o verdadeiro valor do parâmetro é, de fato, 0,75. Estamos apenas adotando esse valor como uma estimativa desse parâmetro, uma vez que, pelo método da máxima verossimilhança, ele é o valor que melhor explica a amostra obtida.
Para concluir, podemos utilizar o R para criar os gráficos das funções de verossimilhança e escore do exemplo acima, para assim termos uma melhor visualização dos resultados obtidos. Definindo as funções, temos:
vero <- function(theta) theta^3*(1-theta)
escore <- function(theta) (3 - 4*theta)/(theta*(1 - theta))
Para plotarmos os gráficos, utilizaremos a função curve, do pacote básico graphics, a qual desenhará uma curva para a função especificada em um dado intervalo. Para ambas as funções que queremos plotar, como 0⩽θ⩽1, não precisaremos especificar o intervalo que curve utilizará, uma vez que [0,1] é o intervalo padrão dessa função. Com a função abline, traçaremos linhas verticais e horizontais nas coordenadas especificadas, utilizando o argumento lty para especificar se a linha deve ser completa (lty = 1) ou tracejada (lty = 2). Com a função points, adicionaremos ao gráfico pontos nas coordenadas especificadas, utilizando o argumento pch para definir seu formato. Por fim, com a função text, adicionaremos textos ao gráfico, nas coordenadas escolhidas, por meio do argumento labels. Todas as funções aqui utilizadas pertencem ao pacote básico graphics. Para a função de verossimilhança, temos:
curve(expr = vero,
main = “Gráfico da função de verossimilhança”,
xlab = “Theta”, ylab = “Verossimilhança”,
col = “#32A0FF”,
ylim = c(0, 0.12))
abline(v = 0.75, h = 0.10546875, lty = 2)
points(x = 0.75, y = 0.10546875, col = “red”, pch = 20)
text(x = 0.86, y = 0.11, labels = c(“(0.75, 0.10546875)”))
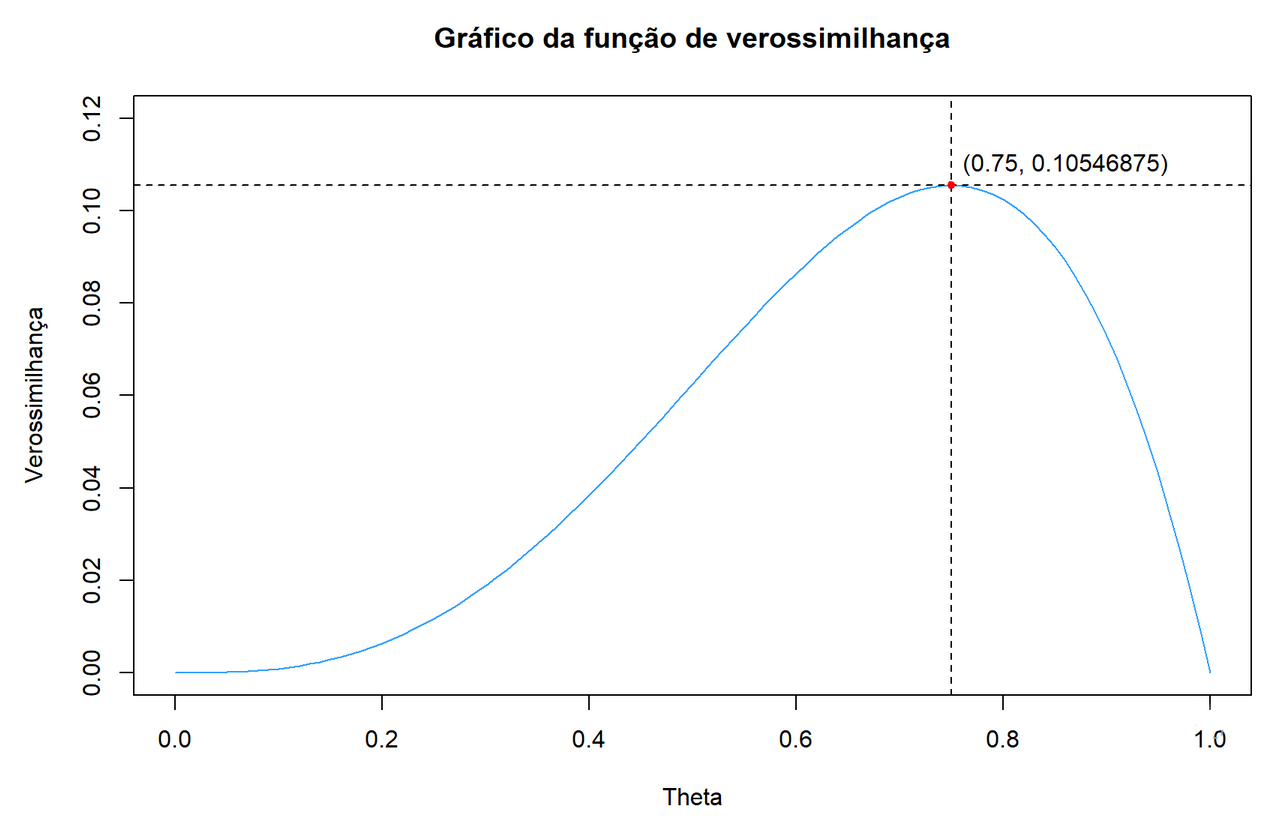
Observe que, de fato, a função de verossimilhança em questão possui um ponto de máximo absoluto em θ=0,75. Já quanto à função escore,
curve(expr = escore,
main = “Gráfico da função escore”,
xlab = “Theta”, ylab = “Escore”,
col = “#32A0FF”)
abline(v = c(0, 0.75), h = 0, lty = c(1, 1, 2))
points(x = 0.75, y = 0, col = “red”, pch = 20)
text(x = 0.805, y = 15, labels = c(“(0.75, 0)”))
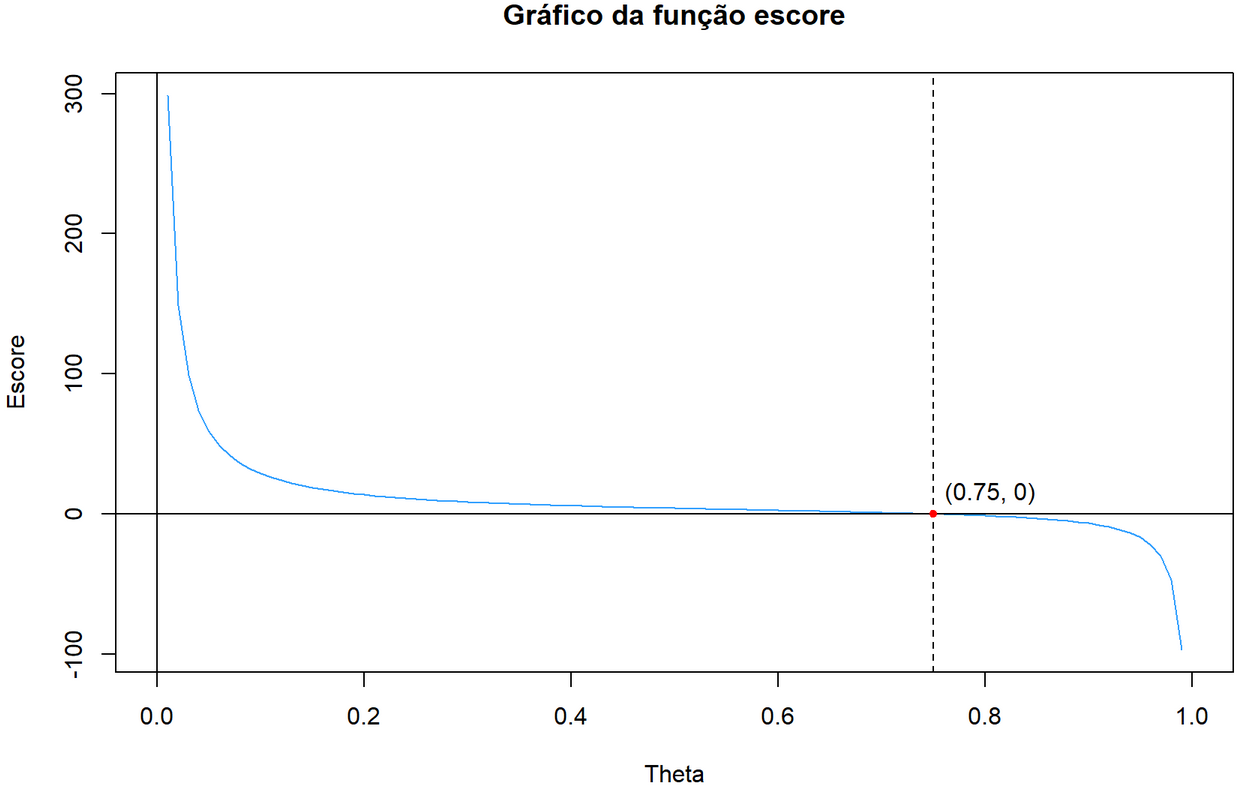
Note que, como esperado, o gráfico da função escore intercepta o eixo x apenas no ponto θ=0,75, o qual, como visto acima, é um ponto de máximo da função de verossimilhança. Dessa forma, podemos observar que os cálculos feitos ao longo do post estão de acordo com as representações visuais das funções envolvidas.
Ao longo desse post, discutimos sobre os conceitos de verossimilhança e função de verossimilhança, demonstrando algumas de suas utilizações dentro da Estatística. Algo que aqui não foi discutido, muito por conta da falta de conhecimento do autor sobre o assunto até o presente momento, é o papel da função de verossimilhança dentro da inferência Bayesiana. Mas isso é papo para outra hora. De qualquer forma, esperamos que as definições e os exemplos aqui apresentados tenham ficado claros, de forma que o leitor tenha conseguido adquirir algum conhecimento sobre essa temática. Para comentários, sugestões e colaborações científicas, entre em contato conosco através do e-mail observatorioobstetricobr@gmail.com.
https://fsbmat-ufv.github.io/blog_posts/14-08-2019/post1
https://en.wikipedia.org/wiki/Likelihood_function
https://online.stat.psu.edu/stat415/lesson/1/1.2
MOOD, Alexander McFarlane. Introduction to the theory of statistics. 3. ed. EUA: McGraw-Hill Education, 1974. 480 p.