
Linguagem R

09/03/2023
Linguagem R
Neste post, vamos falar sobre uma ferramenta simples, mas poderosa: a tabela de contingência, também conhecida como tabela cruzada. Entender o seu funcionamento, e principalmente, como interpretá-la é fundamental. Com a tabela cruzada é possível obter diversas informações de duas variáveis de interesse como, a frequência absoluta das categorias, as porcentagens, o total de cada grupo, entre outros. Por exemplo, pensando nas eleições e limitando a um cenário bem simples, a tabela cruzada pode nos ajudar a entender se a distribuição de eleitores votantes no candidato A difere entre eleitores do gênero feminino e masculino.
De uma maneira mais formal, tabela cruzada é utilizada quando estamos trabalhando com duas variáveis categóricas em que se deseja investigar a sua relação conjunta. Para exemplificar, vamos ao seguinte cenário: estamos analisando dados de gestantes e puérperas com Síndrome Respiratória Aguda Grave (SRAG) e queremos avaliar a relação entre as variáveis febre (exposição) e evolução (desfecho). A variável febre tem as categorias “sim” e “não” e evolução tem as categorias “cura” e “obito”. Como cada variável tem duas categorias cada, isso irá gerar uma tabela 2×2. Veja como fica:

Essa tabela foi retirada do nosso painel OOBr SRAG na aba de análise cruzada.
Para os exemplos, vamos utilizar os dados que correspondem a registros de gestantes e puérperas de 10 a 55 anos hospitalizadas com SRAG por COVID-19 confirmada por teste de PCR. Esta base de dados foi tratada e todo o tratamento feito será disponibilizado em nosso livro Ciência de Dados Aplicada à Saúde Materno-Infantil, disponível em https://observatorioobstetricobr.org/livro-e-tutoriais/.

Antes de entendermos as intersecções, precisamos nos atentar aos totais. Veja que temos “Total” tanto na coluna quanto na linha. O “Total” da linha soma todas as informações daquela coluna, por exemplo, o valor 3254 é o total de casos com o desfecho cura, já o valor 575 representa o total dos casos que tiveram desfecho óbito. O “Total” que aparece na coluna é a soma das informações da linha. O valor 2199 neste caso representa a soma dos casos que não tiveram febre, já o valor 1630 é o total de casos que tiveram febre. Por fim, o valor na casela de “Total” da linha e coluna é o total de casos, ou seja, temos aqui 3829 casos.
A contagem na intersecção da linha i e coluna j é identificada por nij com i,j = 1,2 e representa o número de observações que exibem essa combinação de níveis. Por exemplo, a casela da primeira linha e da primeira coluna é a intersecção entre gestantes e puérperas que não tiveram febre e que evoluíram para cura. A porcentagem pode ser tanto por linha quanto por coluna. Veja que neste caso está por linha, pois os valores de 100% estão dispostos em cada linha. Certo, agora já podemos então formular a interpretação desta tabela com as porcentagens por linha da seguinte forma: “dado que a minha exposição foi a eu tive y de desfecho”, onde a representa a minha categoria de exposição e y
a contagem da intersecção. Voltando para o exemplo, podemos interpretar a tabela da seguinte forma: “dado o grupo de gestantes que tiveram febre (n= 2199), 1848 (84.0%) evoluíram para cura; dado o grupo que teve febre (n= 2199), 351 (16.0%) evoluíram para óbito. Dado o grupo de gestantes que não tiveram febre (n = 1630), 9553 1406 (86.3%) evoluíram para cura; dado o grupo que teve febre, 224 (13.7%) evoluíram para óbito.
Agora vamos ao cenário onde a porcentagem está por coluna.

Observe que a disposição das variáveis e seus valores brutos continuam iguais, o que muda são as porcentagens e os totais. Nesta tabela, a porcentagem está por coluna, veja que que o total (100%) está em cada coluna. A interpretação em relação às porcentagens fica diferente em relação à tabela anterior. Interpretamos as porcentagens da seguinte maneira: Dentre as gestantes e puérperas que evoluíram para cura, 56.8% tiveram febre e dentre as gestantes e puérperas que evoluíram para cura, 43.2% não tiveram febre. Dentre as gestantes e puérperas que vieram a óbito, 61% tiveram febre e dentre as gestantes e puérperas que vieram a óbito, 39% não tiveram febre.
É muito importante se atentar a distribuição das porcentagens, se está por linha ou por coluna, pois isso muda a maneira com que interpretamos os dados.
A maneira talvez mais simples de criar a tabela é utilizando a função table do R base. Para isto, basta utilizar como argumentos as suas variáveis. Neste caso utilizamos a variável obesidade, que indica se a paciente possui a condição de obesidade ou não e febre que indica se a paciente teve febre ou não. Para as duas variáveis temos a classifição “ignorado”, ou seja, a informação foi ignorada por alguma razão. Para ficar mais fácil de exemplificar, vamos remover essas observações.
dados <- dados |>
dplyr::filter(puerpera != “ignorado”) |>
dplyr::filter(febre != “ignorado”) |>
dplyr::filter(obesidade != “ignorado”) |>
dplyr::mutate(puerpera = droplevels(puerpera)) |>
dplyr::mutate(febre = droplevels(febre)) |>
dplyr::mutate(obesidade = droplevels(obesidade))
table(dados$obesidade, dados$febre)

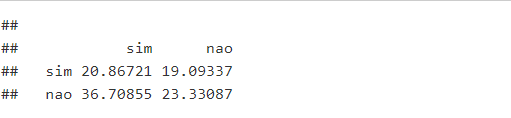
Podemos também fazer a tabela obtendo as porcentagens no lugar das frequências de maneira semelhante, basta utilizar a função prob.table. Neste caso, estamos obtendo a porcentagem em relação ao total.
Podemos exibir essa tabela em um formato um pouco mais bonito, em um relatório por exemplo, utilizando a função kable do pacote knitr.
tabela <- table(dados$puerpera, dados$febre)
knitr::kable(tabela)

Para finalizar, a função ctable() do pacote summarytools pode ser uma excelente escolha para criar uma tabela de contingência. Ela permite que criemos uma tabela parecida com aquela usada nos exemplos acima, contendo informações de valores faltantes (NA), porcentagens e total. A função possui diversos argumentos e permite a inclusão ou não informações na tabela. Para utilizá-la, caso não tenha o pacote instalado, o primeiro passo é instalá-lo por meio da função instal.packages(summarytools) Após isso, basta carregá-lo utilizando a função library(summarytools). Veja alguns exemplos
ctable(
x = dados$puerpera,
y = dados$febre
)

Aqui temos a tabela sem nenhuma configuração, utilizando o “default” para todos os argumentos. Como mencionamos no início do post, é crucial estar atento aos totais. Neste caso, como utilizamos o “default”, as porcentagens estão por linhas. Caso queira colocar por coluna basta utilizar o argumento prop = “c”, veja abaixo:
ctable(
x = dados$puerpera,
y = dados$febre,
prop = “c”
)

Como mencionamos, a tabela é bem customizável. Veja outro exemplo:
knitr::kable(ctable(
x = dados$puerpera,
y = dados$febre,
prop = “n”,
totals = FALSE,
headings = FALSE,
useNA = “no”
))
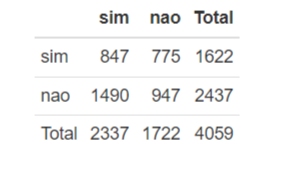
Aqui optamos omitir algumas informações, ficando com uma tabela mais compacta. Você pode ver mais sobre os argumentos da função rodando ?ctable no seu console, ou até mesmo procurando no google. Ainda combinamos com a função kable para ficar mais “apresentável”.
ctable(
x = dados$puerpera,
y = dados$febre,
prop = “n”,
OR = TRUE,
RR = TRUE,
chisq = TRUE
)
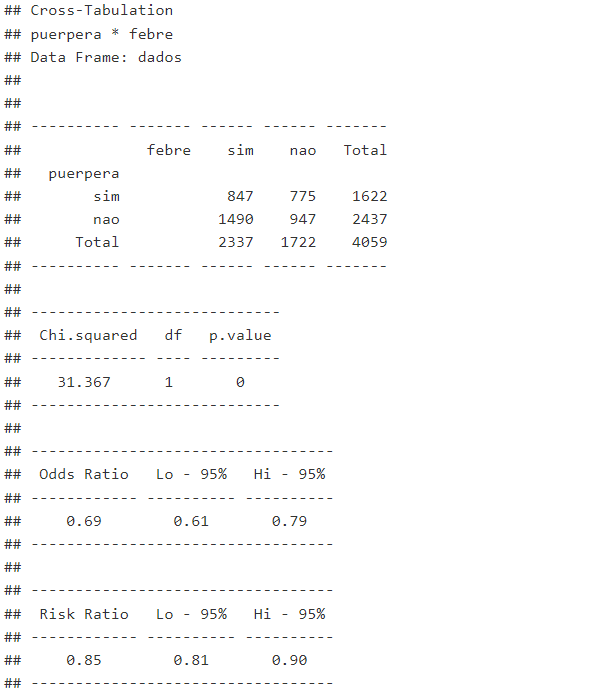
Para finalizar, através dos argumentos OR, RR, E CHISQ, é possível calcular a odds ratio (razão de chances), risco relativo e o teste qui-quadrado, respectivamente. Veja que ao adicionar estes argumentos, temos como saída a tabela cruzada, logo abaixo o teste qui-quadrado, a odds ratio com intervalo de confiança, onde Lo – 95% é o limite inferior do intervalo de confiança com nível de confiança de 95% e Hi – 95 é o limite superior do intervalo de confiança com nível de confiança de 95%. Por último, é exibido o risco relativo também com seu respectivo intervalo de confiança. Recomendamos que você leia o nosso post sobre Risco Relativo e Odds Ratio: como calcular e suas principais diferenças lá você irá aprender tudo sobre Risco Relativo e Odds Ratio e, além disso, verá como a tabela de contingência pode nos ajudar a interpretar essas informações. Como é exibido também intervalos de confiança, recomendamos também o nosso post Intervalos de confiança.

